How are research-based assessment instruments developed and validated?

How are research-based assessments instruments of content and beliefs developed and validated?
Good research-based assessment instruments (RBAIs) are different from typical exams in that their creation involves extensive research and development by experts in Physics Education Research (PER) and/or Astronomy Education Research (AER) to ensure that the questions represent concepts that faculty think are important, responses represent real student thinking and make sense to students, and that students’ scores reliably tell us something about their understanding. The typical process of developing a research-based assessment of content or beliefs includes the following steps (Adams and Wieman 2011; Engelhardt 2009)
- Gathering students’ ideas about a given topic, usually with interviews or open-ended written questions.
- Using students’ ideas to write multiple-choice conceptual questions where the incorrect responses cover the range of students’ most common incorrect ideas using the students’ actual wording.
- Testing these questions with another group of students. Usually, researchers use interviews where students talk about their thinking for each question.
- Testing these questions with experts in the discipline to ensure that they agree on the importance of the questions and the correctness of the answers.
- Revising questions based on feedback from students and experts.
- Administering assessment to large numbers of students. Checking the reproducibility of results across courses and institutions. Checking the distributions of answers. Using various statistical methods to ensure the reliability of the assessment.
- Revising again.
Beichner described a similar process for developing RBAIs that might also be of interest to a new RBAI developer (Beichner 1994). This rigorous development process produces valid and reliable assessments that can be used to compare instruction across classes and institutions.
How are observations protocols developed and validated?
Observation protocols on PhysPort are all developed using research-based approaches but there are differences in how they are developed, structured, and used as compared to assessments of content and beliefs. Further, there is a lot more variety in how individual observation protocols developed and validated. Here are some commonalities in that process:
- Draft protocol items based on existing protocols, unstructured observations of students or faculty focusing on a certain aspect of their behavior or developers write items to focus on a particular theoretical construct that they want to capture.
- Initial items are often reviewed by experts and revised (often several times).
- Initial draft of the protocol is used by more than one observer in the same classroom.
- Results of observations are compared between multiple observers. Discrepancies are discussed and protocol items are revised.
- Protocol is used in more classroom observations (and possibly in different disciplines or institutions and by different observers), and revised until observers have strong agreement between one another, and are confident that the observation protocol is capturing what the developers intended. Often an inter-rater reliability metric is calculated.
- Developers look at some measure of the validity, e.g., comparing the observation results to another measure, looking at how observation results predict the results of another measure etc.
- Developers create training materials to help new users use the protocol correctly and revise them as appropriate.
How are research validation summaries determined on PhysPort?
Based on the steps to developing a good research-based assessment, we have created a list of seven categories of research validation for assessments of content and beliefs (Table 1). Each of these categories says different things about the research validation behind the instrument. “Studied with student interviews” and “questions based on research into student thinking” are two different ways of connecting test questions with students’ ideas. “Studied with expert review” ensures that the questions are relevant to physics educators. “Appropriate use of statistical analysis” compares students’ performance on the questions in a robust way. “Administered at multiple institutions” ensures that the RBAI is applicable to more than one institution. “Research published by someone other than developers” and “at least one peer-reviewed publication” are two different ways of measuring community buy-in about the research behind the RBAI. Different members of the research community value these different methods in different ways. Several articles discuss the affordances and constraints of these categories in more depth (Adams and Wieman 2011; Engelhardt 2009; Lindell, Peak, and Foster 2006)
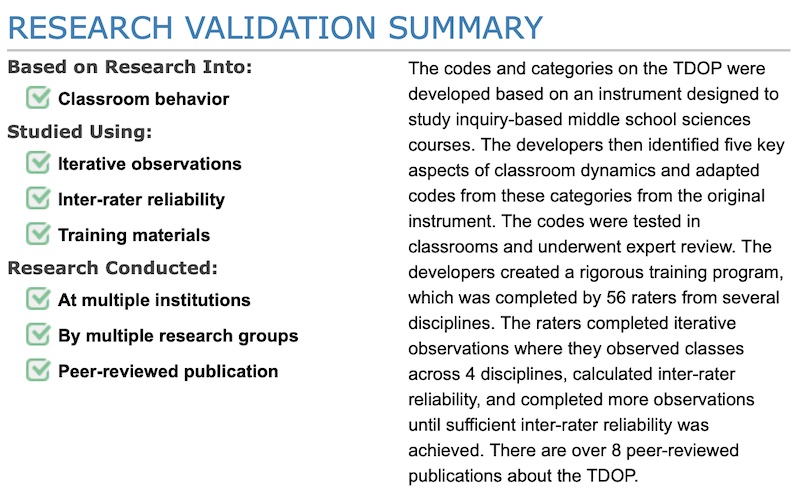
We have developed separate levels of research validation for observation protocols because the development process for these is substantially different than for the other kinds of assessments. Because faculty, and not students, use protocols, it does not make sense to look at student thinking or do student interviews. Instead, when developing observation protocols, it is vital to ensure that the categories of observation are grounded in real classrooms. The protocol is iteratively developed through use in real classrooms, there is a high level of inter-rater reliability (which means that the observers can interpret and apply the protocol similarly), and the training materials for using the protocol have been tested and refined. To reflect the differences between observation protocols and other types of RBAIs, we developed a parallel set of research validation categories for observation protocols.
Table 1. Research validation categories for different types of assessments
|
Categories for content, belief, and reasoning RBAIs |
Categories for observation protocols |
Categories for rubrics |
| Questions based on research into student thinking |
Categories based on research into classroom behavior |
Items based on relevant theory and/or data |
| Studied with student interviews |
Studied using iterative observations |
Tested and refined through iterative use of rubric |
| Studied with expert review |
Tested using inter-rater reliability |
Tested using inter-rater reliability |
| Appropriate use of statistical analysis |
Training materials are tested |
Studied with expert review |
| Research conducted at multiple institutions | ||
| Research conducted by multiple research groups | ||
| At least one peer-reviewed publication | ||
We determine the level of research validation for an assessment based on how many of the research validation categories apply to the RBAI (Table 2). RBAIs will have a gold level validation when they have been rigorously developed and recognized by a wider research community. Silver-level RBAIs are also well-validated, but are missing 1 and 2 levels of research validation. In many cases, silver RBAIs have been validated by the developers but not the larger community, often because these assessments are new. Bronze-level assessments are those where developers have done some validation but are missing pieces. Finally, research-based validation means that an assessment is likely still in the early stages. While the research validation category given for each assessment in this paper is informative, you may be interested in knowing exactly what levels of research validation were completed for a particular assessment. To do this, go to the research tab on the PhysPort assessment you are interested in. There you will find a list of the validation categories indicating which have been completed, and a short description of the research done for that assessment (Figure 1).
Table 2. Determination of the level of research validation for an assessment on PhysPort.
| # Categories | Research validation level |
| All 7 | Gold |
| 5-6 | Silver |
| 3-4 | Bronze |
| 1-2 | Research-based |
Figure 1. Examples of research validation summary for an assessment of content, the FMCE from PhysPort.

Figure 2. Examples of research validation summary for an observation protocol, the TDOP from PhysPort.
References
- W. Adams and C. Wieman, Development and Validation of Instruments to Measure Learning of Expert-Like Thinking, Int. J. Sci. Educ. 33 (9), 1289 (2011).
- R. Beichner, Testing student interpretation of kinematics graphs, Am. J. Phys. 62 (8), 750 (1994).
- P. Engelhardt, An Introduction to Classical Test Theory as Applied to Conceptual Multiple-choice Tests, in Getting Started in PER, edited by C. Henderson and K. Harper, (American Association of Physics Teachers, College Park, 2009), Vol. 2.
- R. Lindell, E. Peak, and T. Foster, Are They All Created Equal? A Comparison of Different Concept Inventory Development Methodologies, presented at the Physics Education Research Conference 2006, Syracuse, New York, 2006.
 Add a Comment
Add a Comment


